
Page 13 - ChipScale_Nov-Dec_2020-digital
P. 13
than the caches in generalized processors, number of training examples, throughput the number of parallel workers, high
which guess at the best data to store, is key. On the other hand, inference has bandwidth communication between AI
on-chip memory scratchpads storing fewer data structures, involving only the chips also becomes a critical bottleneck
precisely predictable data can be used forward pass. If possible, storage of the where heterogeneous integration can help.
to optimize data flow and maximize full DNN model near memory is highly For example, in data parallelism, each
data reuse. Finally, it has been amply desirable to reduce latency and minimize worker takes a subset of the training data
demonstrated that AI applications simply the energy cost of data movement. Low and determines the changes to the model
do not need the high precision required latency is of prime importance for many for its part of the data. However, as the
for many other workloads; the state of inference applications because of the training proceeds, these weight changes
the art is to use 8 bits for training [4] need for real-time processing. must be exchanged and synchronized
and 4 bits (with even 2 bits possible) Although great strides have been so that all workers have an updated
for inference [5] while preserving the made in accelerating AI workloads copy of the model. Several topologies
accuracy achieved at higher precisions. through compute units such as GPUs such as hypercube mesh and torus with
The use of lower precision leverages the and specialized accelerators, it is equally high-speed links are being employed to
quadratic scaling of compute energy and important to increase the memory optimize chip-to-chip communication [9].
area with the number of bits. bandwidth in tandem; otherwise the To summarize this section, AI compute
W i t h t h e s e d r i v e r s , s e v e r a l compute units can remain idle waiting requires dense compute modules capable
specialized components including for data, leading to unbalanced system of accelerating operations common to
graphics processing units (GPUs), field- performance. To support the high DNNs, such as matrix multiplication.
programmable gate arrays (FPGAs), bandwidth requirements, memories such as AI memory demands high bandwidth
and AI accelerators have been widely the high bandwidth memory (HBM) have to match the compute throughput and
deployed to accelerate AI workloads. been introduced [6]. An illustrative study high capacity to support large DNN
Because of the huge computational found that, over a 10-year period, GPU models. Finally, large training jobs
requirements, training workloads are compute performance increased by 41x require multiple chips connected by high-
often parallelized among multiple while bandwidth increased only 10x [7]. To bandwidth, energy-efficient interfaces.
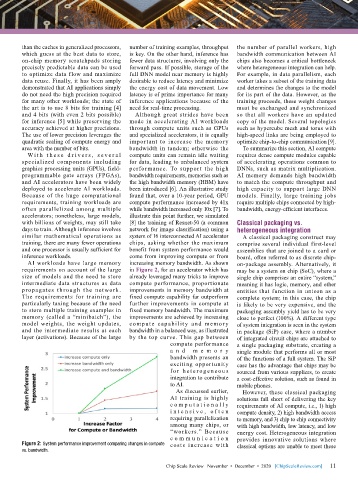
accelerators; nonetheless, large models, illustrate this point further, we simulated
with billions of weights, may still take [8] the training of Resnet-50 (a common Classical packaging vs.
days to train. Although inference involves network for image classification) using a heterogeneous integration
similar mathematical operations as system of 16 interconnected AI accelerator A classical packaging construct may
training, there are many fewer operations chips, asking whether the maximum comprise several individual first-level
and one processor is usually sufficient for benefit from system performance would assemblies that are joined to a card or
inference workloads. come from improving compute or from board, often referred to as discrete chip-
AI workloads have large memory increasing memory bandwidth. As shown on-package assembly. Alternatively, it
requirements on account of the large in Figure 2, for an accelerator which has may be a system on chip (SoC), where a
size of models and the need to store already leveraged many tricks to improve single chip comprises an entire “system,”
intermediate data structures as data compute performance, proportionate meaning it has logic, memory, and other
propagates th rough the net work. improvements in memory bandwidth at entities that function in unison as a
The requirements for training are fixed compute capability far outperform complete system; in this case, the chip
particularly taxing because of the need further improvements in compute at is likely to be very expensive, and the
to store multiple training examples in fixed memory bandwidth. The maximum packaging assembly yield has to be very
memory (called a “minibatch”), the improvements are achieved by increasing close to perfect (100%). A different type
model weights, the weight updates, compute capabilit y a nd memor y of system integration is seen in the system
and the intermediate results at each bandwidth in a balanced way, as illustrated in package (SiP) case, where a number
layer (activations). Because of the large by the top curve. This gap between of integrated circuit chips are attached to
compute performance a single packaging substrate, creating a
a nd m e mo r y single module that performs all or most
bandwidth presents an of the functions of a full system. The SiP
exciting opportunity case has the advantage that chips may be
f o r h e t e r o g e n e ou s sourced from various suppliers, to create
integration to contribute a cost-effective solution, such as found in
to AI. mobile phones.
As discussed earlier, However, these classical packaging
AI training is highly solutions fall short of delivering the key
c om p u t a t i o n a l l y requirements of AI compute, i.e., 1) high
i n ten s i v e , o f ten compute density, 2) high bandwidth access
requiring parallelization to memory, and 3) chip to chip connectivity
among many chips, or with high bandwidth, low latency, and low
“workers.” Because energy cost. Heterogeneous integration
c o m m u ni c a t i o n provides innovative solutions where
Figure 2: System performance improvement comparing changes in compute costs increase with classical options are unable to meet these
vs. bandwidth.
Chip Scale Review November • December • 2020 [ChipScaleReview.com] 11 11